

1. 목표
현재 ChatGPT를 활용하여 디자이너의 포트폴리오를 피드백하는 서비스를 개발 중이다.
피드백의 정확도를 높이기 위해, 포트폴리오에 포함된 이미지를 대상으로 OCR(문자 인식) 처리를 수행하여 텍스트를 함께 ChatGPT에 전달하는 방식을 도입하였다.
포트폴리오 파일이 업로드되면, 해당 파일을 이미지로 슬라이싱하고 이를 NCP Object Storage에 업로드하는 과정까지는 API 서버에서 처리하고 있고, Object Storage 버킷에 저장된 슬라이싱된 이미지들을 대상으로 OCR 서비스를 호출해 텍스트를 추출하는 추가적인 로직이 필요하다.
이 과정을 API 서버에서 처리할 수도 있지만, 인프라 단에서 서버리스 방식으로 간결하고 효율적으로 처리할 수 있다고 판단하여 NCP의 Cloud Functions를 도입하기로 하였다.
이를 통해 이미지 업로드 이벤트를 감지하여 자동으로 OCR 처리를 수행하고, 추출된 텍스트를 후속 피드백 로직에 활용할 수 있는 구조를 구성하고 있다.
2. Naver Cloud Platform
디프만에서 NCP와의 제휴를 통해 크레딧을 지원해주고 있어 모든 인프라 리소스는 NCP를 이용하고 있다.
2-1. NCP Cloud Functions 서비스
특정 이벤트가 발생했을 때 자동으로 코드를 실행하는 서버리스(Serverless) 컴퓨팅 서비스
Cloud Functions는 NCP의 Lamba(AWS Serverless 서비스)라고 생각하면 된다.
특정 이벤트를 감지해 자동으로 코드를 실행하므로 서버를 만들거나 유지보수하지 않아도 되고, 코드 작성과 이벤트 연결만 하면 끝이다..!
여기서, 이벤트를 감지하는 부분은 'Trigger'가 담당하고, 코드는 'Action'이 담당한다.
Trigger는 이벤트를 감지하고 액션을 실행시키는 이벤트 연결 장치로, 전달된 이벤트 데이터는 각 액션의 입력 파라미터로 사용된다.
Action은 이벤트에 반응하거나 직접 호출해 실행시킬 수 있는 사용자 코드다.
현재 JavaScript, Swift, Java, Python, PHP 등의 언어를 지원하고, Container Registry에서 이미지를 가져올 수도 있다.
(Java는 압축된 .jar 파일 형태로만 등록 가능하고, .net(dotnet)의 경우에는 압축파일(.zip) 형태로만 업로드가 가능하다.)
2-2. NCP Clova OCR 서비스
전송한 문서나 이미지를 인식하여 사용자가 지정한 영역의 텍스트와 데이터를 정확하게 추출하는 서비스
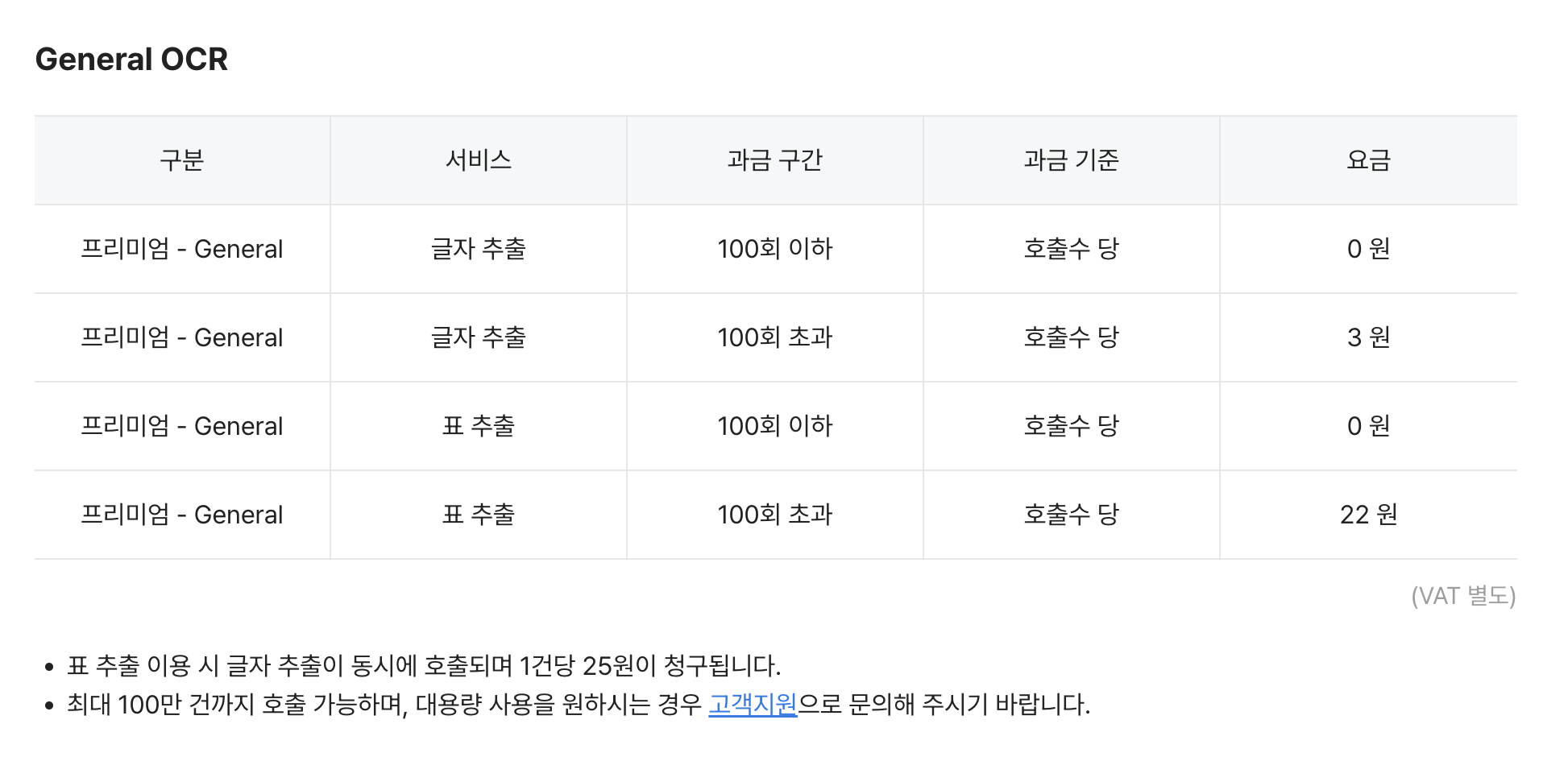
가격은 아래와 같다.
OCR API 사용 방법
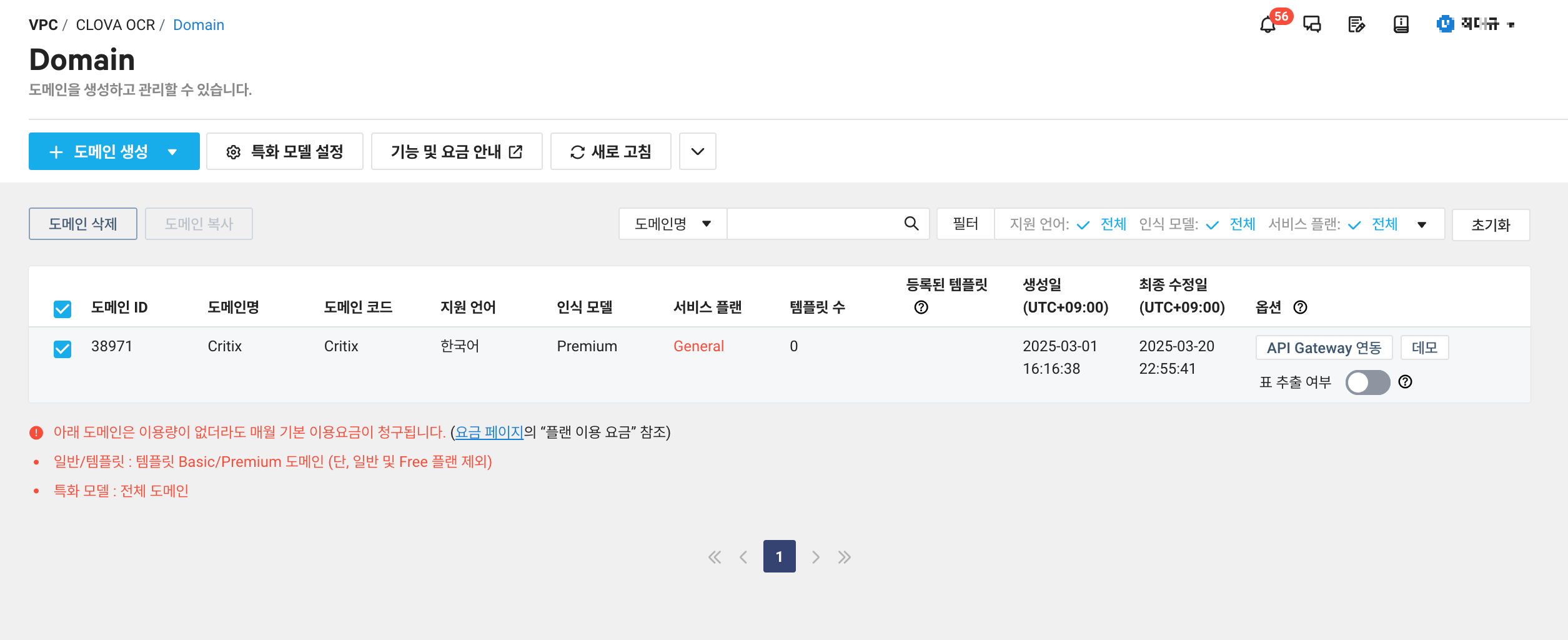
1. Domain 생성
Domain을 생성한 뒤옵션에 있는 API Gateway 연동을 선택한다.
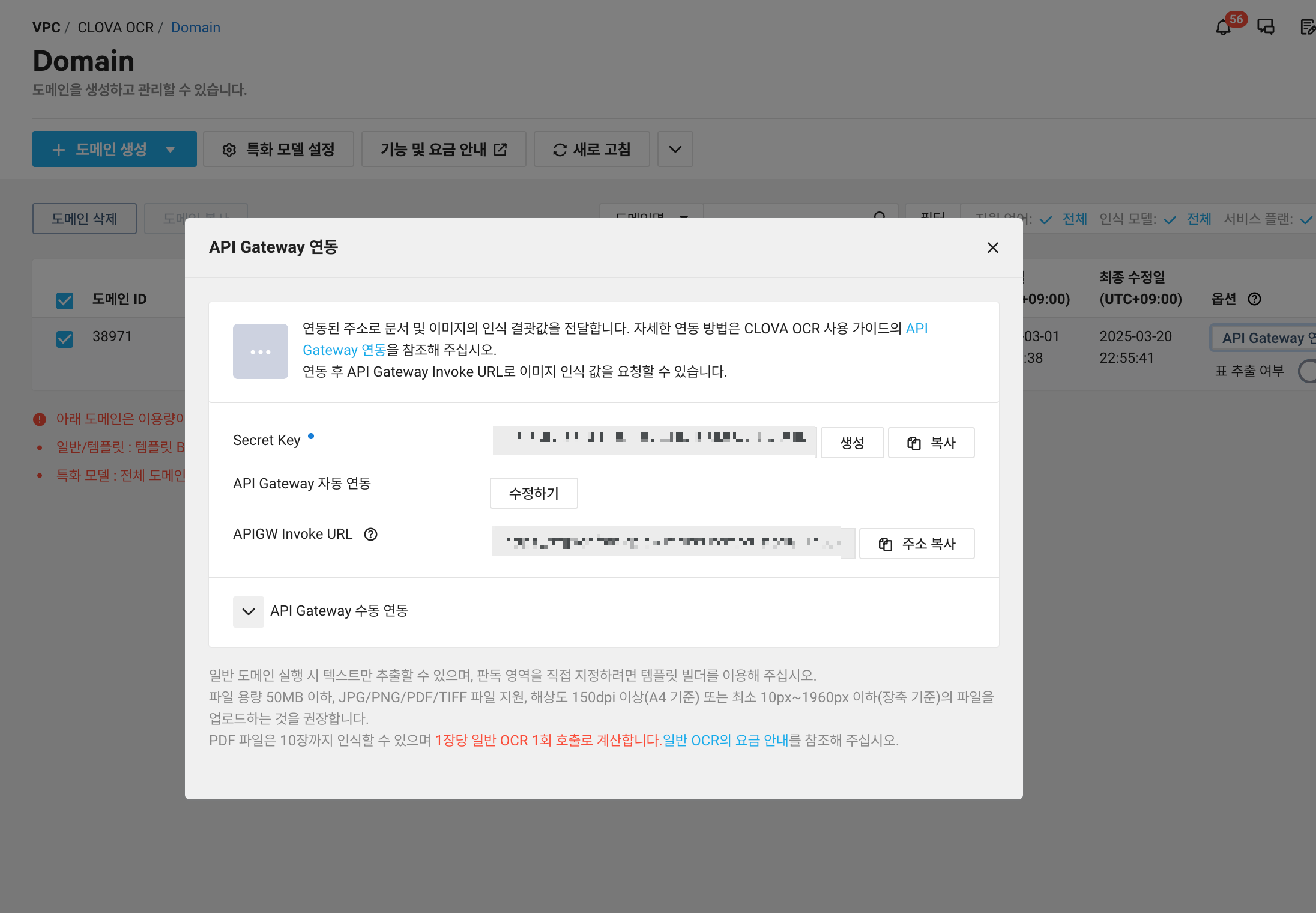
1. API 호출
발급한 Secret Key와 Invoke URL을 저장해둔 뒤 이를 이용해 API 호출을 하면 된다.
[API 호출 방법]
POST
URL : Invoke URL
Header : X-OCR-SECRET, Content-Type
Body
{
"images": [
{
"format": "png",
"name": "medium",
"data": null,
"url":
"이미지 url"
}
],
"lang": "ko",
"requestId": "string",
"resultType": "string",
"timestamp": "{{$timestamp}}",
"version": "V1"
}3. Cloud Functions 흐름
1. S3 이벤트 트리거 설정
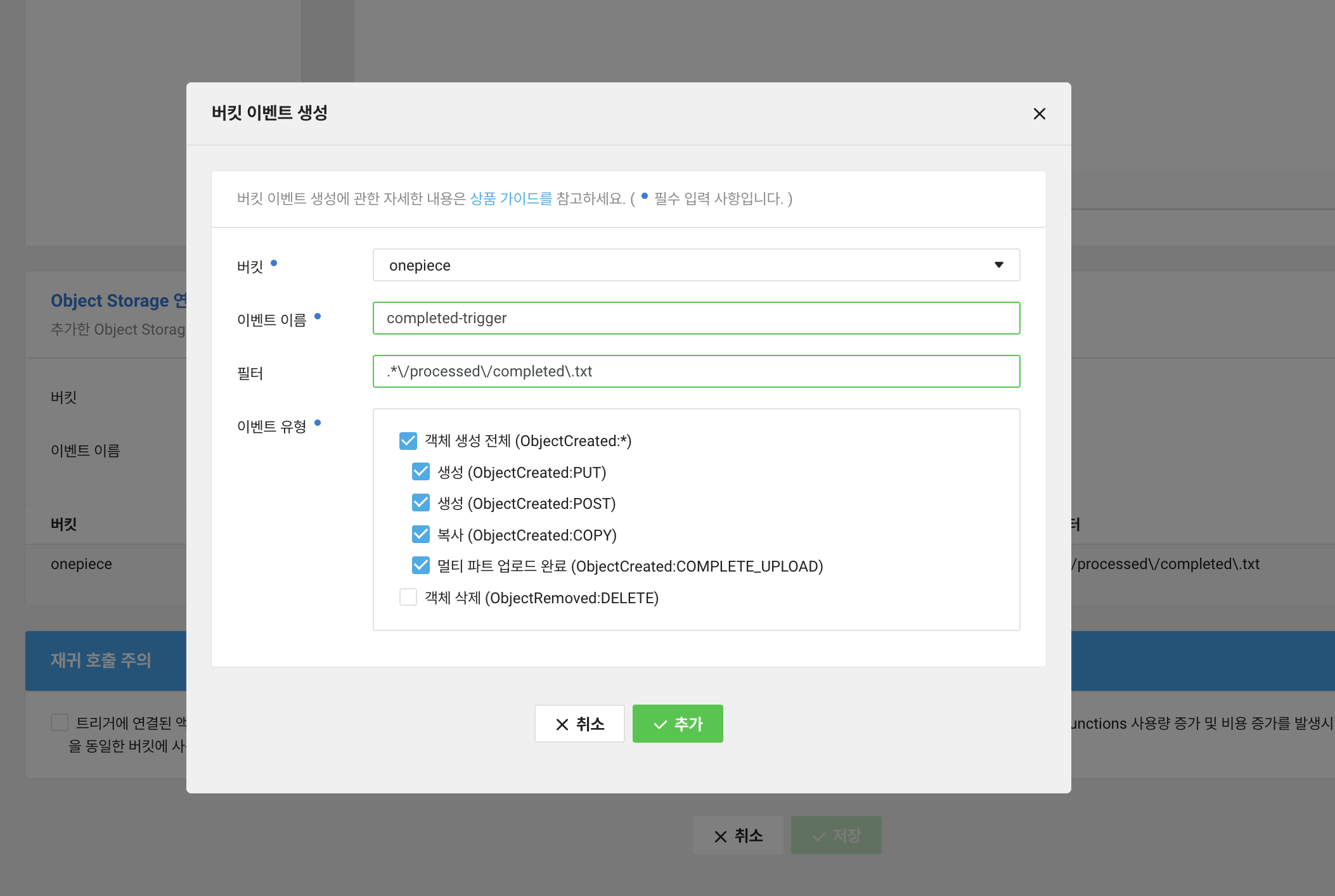
포트폴리오 파일에서 이미지 슬라이싱이 완료되면 해당 버킷에 completed.txt 파일을 업로드하여 업로드가 완료되었다는 트리거로 사용한다.
Cloud Functions 버킷 이벤트 생성을 누르고 정규표현식으로 필터를 걸어주면 된다.
userId/processed 위치에 업로드할 예정이기 때문에 '.*\/processed\/completed\.txt'로 넣어주었다.
2. Cloud Function 액션
빠른 개발을 위해 파이썬으로 작성하였고, NCP에는 액션을 테스트할 수는 없기 때문에 로컬에서 테스트한 뒤 올려주었다.
[S3 객체 목록 조회]
- boto3의 'list_objects_v2'를 이용해 해당 버킷의 객체 목록을 조회한다.
[각 이미지에 대해 Presigned GET URL 발급]
- 이미지 접근을 위해 버킷의 이미지들에 대해 PresignedUrl을 발급한다.
- 발급받은 PresignedUrl은OCR API을 호출할 때 사용한다.
[OCR 요청 병렬 처리]
- 이미지 수가 보통 50장 이상이기 때문에 병렬로 처리한다.
- ThreadPoolExecutor을 사용했다.
- 요청이 실패할 경우 최대 1회까지 재시도하는 로직을 추가했다.
[OCR 결과를 JSON으로 만들어 버킷에 업로드]
- OCR 결과를 합쳐 json 파일로 만든 뒤 버킷에 업로드한다.
3. Action 코드 구현
1. 환경 설정 및 클라이언트 초기화
환경변수를 불러오고 boto3를 이용해 S3 클라이언트를 생성해주었다.
NCP Object Storage는 S3 SDK와 호환되기 때문에 boto3를 사용하면 된다.
import os
import json
import time
import requests
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
import boto3
# S3 기본 설정
endpoint_url = "https://kr.object.ncloudstorage.com"
bucket_name = os.environ['bucket_name']
access_key = os.environ['access_key']
secret_key = os.environ['secret_key']
# OCR API 설정
ocr_api_url = os.environ['ocr_api_url']
ocr_secret = os.environ['ocr_secret']
headers = {
"Content-Type": "application/json",
"X-OCR-SECRET": ocr_secret
}
# S3 클라이언트 생성
s3 = boto3.client(
's3',
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
endpoint_url=endpoint_url
)
2. presigned URL 생성 함수
이미지 접근와 버킷에 json 파일을 업로드하기 위한 presignedUrl을 발급하는 함수다.
만료시간을 설정해 해당 시간 내에만 접근할 수 있어 보안에 이점이 있다.
def get_presigned_url(key):
return s3.generate_presigned_url(
ClientMethod='get_object',
Params={'Bucket': bucket_name, 'Key': key},
ExpiresIn=3600
)
def get_presigned_url_for_put(key):
return s3.generate_presigned_url(
ClientMethod='put_object',
Params={'Bucket': bucket_name, 'Key': key, 'ContentType': 'application/json'},
ExpiresIn=3600
)
3. OCR API 호출 함수 (단일 이미지 처리)
OCR Domain 생성 시 발급받은 URL와 Secret Key로 요청하면 된다.
요청 실패 시 최대 retry_count + 1번 (최대 2번까지) 재시도하게 하였고, 응답 중 inferText 값만 추출하여 텍스트 리스트로 반환하게 했다.
def process_image(idx, key, url, retry_count=1):
filename = os.path.basename(key)
payload = {
"images": [
{
"format": "png",
"name": f"image_{idx}",
"url": url
}
],
"lang": "ko",
"requestId": f"req_{idx}",
"resultType": "string",
"timestamp": int(time.time() * 1000),
"version": "V1"
}
for attempt in range(1, retry_count + 2):
try:
res = requests.post(ocr_api_url, headers=headers, json=payload)
if res.status_code == 200:
fields = res.json()['images'][0].get('fields', [])
texts = [f['inferText'] for f in fields]
return filename, texts
else:
print(f"⚠️ OCR 요청 실패 ({filename}) - 시도 {attempt}, 상태코드: {res.status_code}")
except Exception as e:
print(f"⚠️ OCR 예외 발생 ({filename}) - 시도 {attempt}, 오류: {str(e)}")
time.sleep(1)
return filename, [f"OCR failed after {retry_count + 1} attempts"]
4. S3 이벤트 처리 및 OCR 로직 실행
이미지 목록 조회 → 병렬로 OCR 실행 → 결과 저장 및 업로드
완료 시 "result.json" 파일을 생성하고 ocr 폴더에 업로드한다.
def process_s3_upload(event, context):
start_time = time.time()
print("🚀 이벤트 수신:", json.dumps(event, indent=2, ensure_ascii=False))
try:
key = event.get('object_name')
if not key:
return {"result": "error", "message": "object_name not provided in event"}
match = re.match(r"([^/]+)/processed/completed\.txt", key)
if not match:
print("❌ userId 경로 파싱 실패")
return {"result": "invalid path"}
user_id = match.group(1)
prefix = f"{user_id}/processed/"
print(f"📁 S3 목록 조회 중: {prefix}")
try:
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=prefix)
except Exception as e:
return {"result": "s3_list_error", "message": str(e)}
contents = response.get("Contents", [])
image_keys = [obj["Key"] for obj in contents if obj["Key"].endswith(".png")]
if not image_keys:
print("⚠️ 이미지 없음")
return {"result": "no images"}
print(f"✅ 이미지 {len(image_keys)}장 OCR 시작")
ocr_results = {}
with ThreadPoolExecutor(max_workers=4) as executor:
futures = [
executor.submit(process_image, idx, key, get_presigned_url(key))
for idx, key in enumerate(image_keys, start=1)
]
for future in as_completed(futures):
try:
filename, texts = future.result()
ocr_results[filename] = " ".join(texts)
print(f"✅ OCR 완료: {filename}")
except Exception as e:
print(f"❌ OCR 처리 실패 (Thread 내부): {str(e)}")
ocr_results[f"error_{time.time()}"] = f"Exception: {str(e)}"
result_key = f"{user_id}/ocr/result.json"
print("📝 OCR 결과:", result_key, ocr_results)
try:
upload_url = get_presigned_url_for_put(result_key)
except Exception as e:
return {"result": "presigned_url_error", "message": str(e)}
try:
res = requests.put(
upload_url,
data=json.dumps(ocr_results, ensure_ascii=False, indent=2).encode("utf-8"),
headers={'Content-Type': 'application/json'}
)
if res.status_code == 200:
print(f"✅ OCR 결과 presigned URL로 업로드 완료 → {result_key}")
else:
print(f"❌ 업로드 실패: {res.status_code}")
return {"result": "upload error", "status_code": res.status_code}
except Exception as e:
return {"result": "upload_exception", "message": str(e)}
elapsed = round(time.time() - start_time, 3)
print(f"✅ OCR 전체 완료, 처리 시간: {elapsed}s")
return {
"result": "success",
"image_count": len(image_keys),
"processing_time_sec": elapsed
}
except Exception as e:
print(f"❌ 최상위 오류 발생: {str(e)}")
return {"result": "error", "message": str(e)}
5. Cloud Function 진입점
Cloud Functions에서는 실행될 때 main() 함수가 호출되기 때문에 꼭 넣어주어야 한다.
입력 이벤트를 받아 process_s3_upload()가 실행되게 했다.
def main(args):
try:
result = process_s3_upload(args, None)
return result if isinstance(result, dict) else {"result": "invalid_return", "raw": str(result)}
except Exception as e:
print(f"❌ main() 예외 발생: {str(e)}")
return {"result": "error", "message": str(e)}
⬇️ 전체 코드 ⬇️
import os
import json
import time
import requests
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
import boto3
# S3 기본 설정
endpoint_url = "https://kr.object.ncloudstorage.com"
bucket_name = os.environ['bucket_name']
access_key = os.environ['access_key']
secret_key = os.environ['secret_key']
# OCR API 설정
ocr_api_url = os.environ['ocr_api_url']
ocr_secret = os.environ['ocr_secret']
headers = {
"Content-Type": "application/json",
"X-OCR-SECRET": ocr_secret
}
# S3 클라이언트 생성
s3 = boto3.client(
's3',
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
endpoint_url=endpoint_url
)
def get_presigned_url(key):
return s3.generate_presigned_url(
ClientMethod='get_object',
Params={'Bucket': bucket_name, 'Key': key },
ExpiresIn=3600
)
def get_presigned_url_for_put(key):
return s3.generate_presigned_url(
ClientMethod='put_object',
Params={'Bucket': bucket_name, 'Key': key, 'ContentType': 'application/json'},
ExpiresIn=3600
)
def process_image(idx, key, url, retry_count=1):
filename = os.path.basename(key)
payload = {
"images": [
{
"format": "png",
"name": f"image_{idx}",
"url": url
}
],
"lang": "ko",
"requestId": f"req_{idx}",
"resultType": "string",
"timestamp": int(time.time() * 1000),
"version": "V1"
}
for attempt in range(1, retry_count + 2):
try:
res = requests.post(ocr_api_url, headers=headers, json=payload)
if res.status_code == 200:
fields = res.json()['images'][0].get('fields', [])
texts = [f['inferText'] for f in fields]
return filename, texts
else:
print(f"⚠️ OCR 요청 실패 ({filename}) - 시도 {attempt}, 상태코드: {res.status_code}")
except Exception as e:
print(f"⚠️ OCR 예외 발생 ({filename}) - 시도 {attempt}, 오류: {str(e)}")
time.sleep(1)
# 모든 시도 실패 시
return filename, [f"OCR failed after {retry_count + 1} attempts"]
def process_s3_upload(event, context):
start_time = time.time()
print("🚀 이벤트 수신:", json.dumps(event, indent=2, ensure_ascii=False))
try:
key = event.get('object_name')
if not key:
return {"result": "error", "message": "object_name not provided in event"}
match = re.match(r"([^/]+)/processed/completed\.txt", key)
if not match:
print("❌ userId 경로 파싱 실패")
return {"result": "invalid path"}
user_id = match.group(1)
prefix = f"{user_id}/processed/"
print(f"📁 S3 목록 조회 중: {prefix}")
try:
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=prefix)
except Exception as e:
return {"result": "s3_list_error", "message": str(e)}
contents = response.get("Contents", [])
image_keys = [obj["Key"] for obj in contents if obj["Key"].endswith(".png")]
if not image_keys:
print("⚠️ 이미지 없음")
return {"result": "no images"}
print(f"✅ 이미지 {len(image_keys)}장 OCR 시작")
ocr_results = {}
with ThreadPoolExecutor(max_workers=4) as executor:
futures = [
executor.submit(process_image, idx, key, get_presigned_url(key))
for idx, key in enumerate(image_keys, start=1)
]
for future in as_completed(futures):
try:
filename, texts = future.result()
ocr_results[filename] = " ".join(texts)
print(f"✅ OCR 완료: {filename}")
except Exception as e:
print(f"❌ OCR 처리 실패 (Thread 내부): {str(e)}")
ocr_results[f"error_{time.time()}"] = f"Exception: {str(e)}"
result_key = f"{user_id}/ocr/result.json"
print("📝 OCR 결과:", result_key, ocr_results)
# presigned URL로 결과 업로드
try:
upload_url = get_presigned_url_for_put(result_key)
except Exception as e:
return {"result": "presigned_url_error", "message": str(e)}
try:
res = requests.put(
upload_url,
data=json.dumps(ocr_results, ensure_ascii=False, indent=2).encode("utf-8"),
headers={'Content-Type': 'application/json'}
)
if res.status_code == 200:
print(f"✅ OCR 결과 presigned URL로 업로드 완료 → {result_key}")
else:
print(f"❌ 업로드 실패: {res.status_code}")
return {"result": "upload error", "status_code": res.status_code}
except Exception as e:
return {"result": "upload_exception", "message": str(e)}
elapsed = round(time.time() - start_time, 3)
print(f"✅ OCR 전체 완료, 처리 시간: {elapsed}s")
return {
"result": "success",
"image_count": len(image_keys),
"processing_time_sec": elapsed
}
except Exception as e:
print(f"❌ 최상위 오류 발생: {str(e)}")
return {"result": "error", "message": str(e)}
def main(args):
try:
result = process_s3_upload(args, None)
return result if isinstance(result, dict) else {"result": "invalid_return", "raw": str(result)}
except Exception as e:
print(f"❌ main() 예외 발생: {str(e)}")
return {"result": "error", "message": str(e)}
4. 트러블 슈팅
네트워크 구성
Cloud Functions VPC 연결에 들어가면 아래 글이 적혀있다.
VPC를 선택하면 하위의 Subnet 목록을 확인할 수 있습니다. 액션 당 하나의 VPC만 선택할 수 있으며, VPC에 속한 Subnet 중 Private Subnet만 선택 가능합니다. 단, 하나의 Subnet만 추가할 수 있습니다.
VPC 액션에서 인터넷 연결을 위해 Subnet의 NAT Gateway를 설정해야 합니다. VPC/Subnet 생성, 설정 등 자세한 사항은 VPC 상품 설명서에서 확인할 수 있습니다.( 필수 입력 사항입니다.)
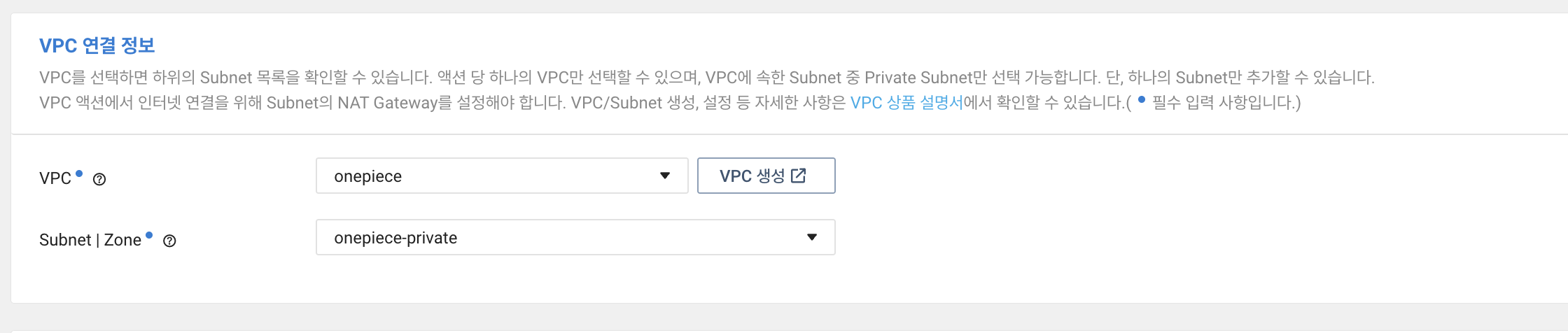
- 1개의 Action은 1개의 VPC를 선택할 수 있고, 해당 서브넷 중 Private 서브넷에만 연결할 수 있다.
- 또한 현재는 VPC 내 KR-2 존에 생성한 Subnet에만 접근할 수 있다.
처음에는 이렇게만 구성을 했었는데 계속 아래와 같이 객체를 가져올 수 없다는 에러가 났다.
{ "message": "Connect timeout on endpoint URL: \"https://kr.object.ncloudstorage.com/onepiece?list~", "result": "error", "stage": "s3_list" }
Cloud Function에서 NCP Object Storage Endpoint로 연결이 안 되고 있어 다시 확인해보니 Cloud Function 실행 환경이 Private VPC에 속해 있기 때문에 외부 인터넷에 접근할 수 없는 것이 원인이었다. (외부와 통신하는 코드가 포함되어 있다.)
따라서, 아래 사진과 같이 NAT Gateway를 만들어 이를 통해 외부로 나갈 수 있게 해주었다.
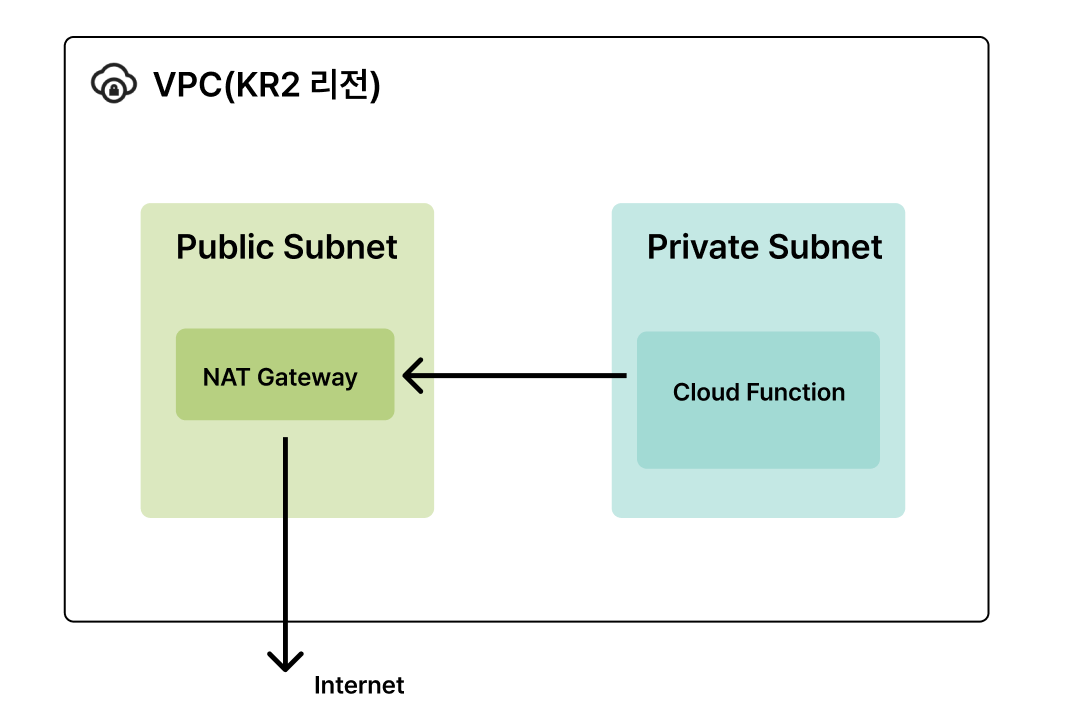
[NAT Gateway 생성]
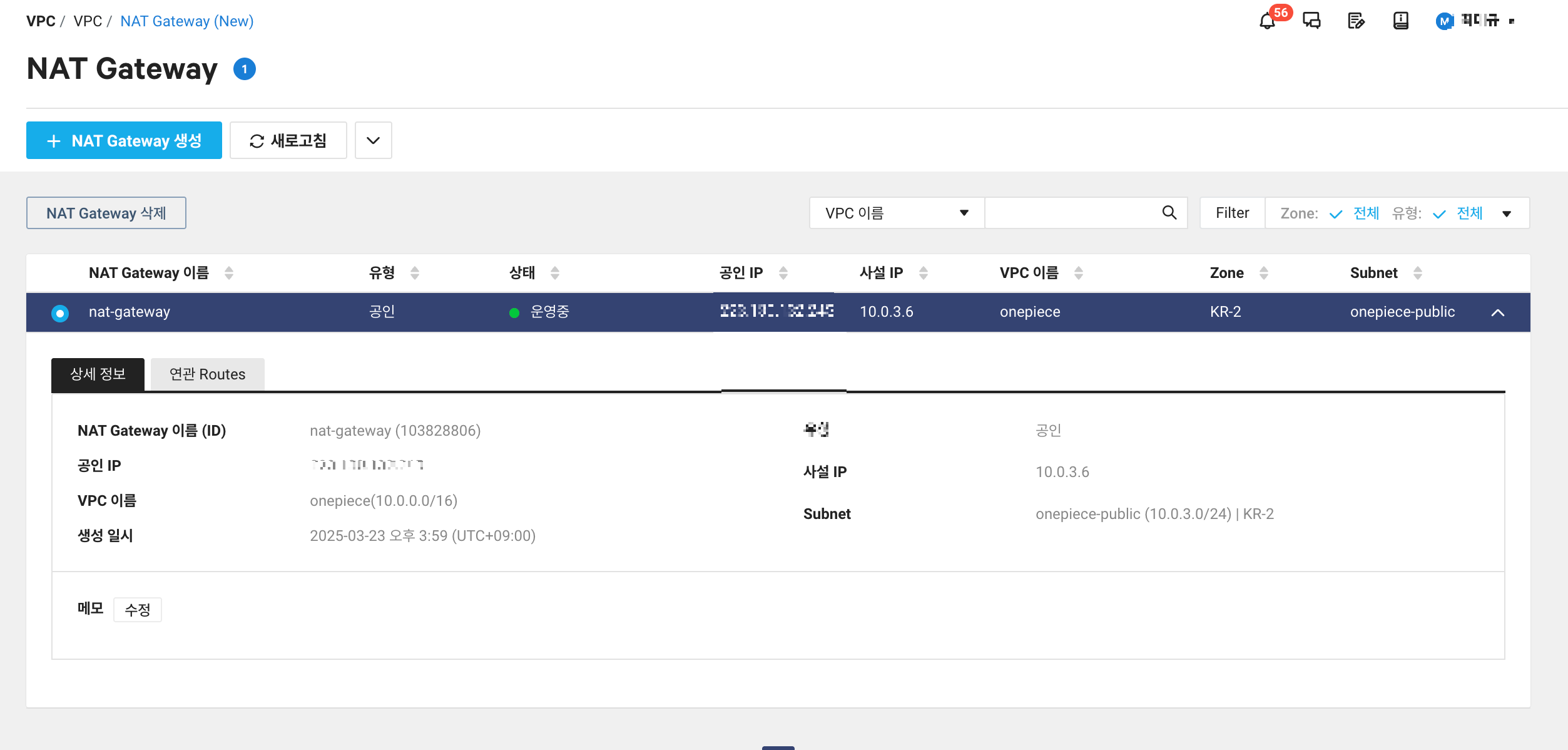
[Route Table에 NAT Gateway 연결]
자동으로 만들어져있는 private-table 라우팅 테이블에 0.0.0.0/0으로 생성한 NAT Gateway를 연결해준다.
이렇게 구성해주니 외부와 잘 통신이 되었다.
'Experience > 디프만' 카테고리의 다른 글
| [NCP] NCP 사용 후기 (디프만 x Green Developers) (0) | 2025.04.10 |
|---|---|
| [코드 포맷팅] spotless로 코드 포맷팅하고 Git Pre-commit으로 자동화하기 (1) | 2025.01.31 |
1. 목표
현재 ChatGPT를 활용하여 디자이너의 포트폴리오를 피드백하는 서비스를 개발 중이다.
피드백의 정확도를 높이기 위해, 포트폴리오에 포함된 이미지를 대상으로 OCR(문자 인식) 처리를 수행하여 텍스트를 함께 ChatGPT에 전달하는 방식을 도입하였다.
포트폴리오 파일이 업로드되면, 해당 파일을 이미지로 슬라이싱하고 이를 NCP Object Storage에 업로드하는 과정까지는 API 서버에서 처리하고 있고, Object Storage 버킷에 저장된 슬라이싱된 이미지들을 대상으로 OCR 서비스를 호출해 텍스트를 추출하는 추가적인 로직이 필요하다.
이 과정을 API 서버에서 처리할 수도 있지만, 인프라 단에서 서버리스 방식으로 간결하고 효율적으로 처리할 수 있다고 판단하여 NCP의 Cloud Functions를 도입하기로 하였다.
이를 통해 이미지 업로드 이벤트를 감지하여 자동으로 OCR 처리를 수행하고, 추출된 텍스트를 후속 피드백 로직에 활용할 수 있는 구조를 구성하고 있다.
2. Naver Cloud Platform
디프만에서 NCP와의 제휴를 통해 크레딧을 지원해주고 있어 모든 인프라 리소스는 NCP를 이용하고 있다.
2-1. NCP Cloud Functions 서비스
특정 이벤트가 발생했을 때 자동으로 코드를 실행하는 서버리스(Serverless) 컴퓨팅 서비스
Cloud Functions는 NCP의 Lamba(AWS Serverless 서비스)라고 생각하면 된다.
특정 이벤트를 감지해 자동으로 코드를 실행하므로 서버를 만들거나 유지보수하지 않아도 되고, 코드 작성과 이벤트 연결만 하면 끝이다..!
여기서, 이벤트를 감지하는 부분은 'Trigger'가 담당하고, 코드는 'Action'이 담당한다.
Trigger는 이벤트를 감지하고 액션을 실행시키는 이벤트 연결 장치로, 전달된 이벤트 데이터는 각 액션의 입력 파라미터로 사용된다.
Action은 이벤트에 반응하거나 직접 호출해 실행시킬 수 있는 사용자 코드다.
현재 JavaScript, Swift, Java, Python, PHP 등의 언어를 지원하고, Container Registry에서 이미지를 가져올 수도 있다.
(Java는 압축된 .jar 파일 형태로만 등록 가능하고, .net(dotnet)의 경우에는 압축파일(.zip) 형태로만 업로드가 가능하다.)
2-2. NCP Clova OCR 서비스
전송한 문서나 이미지를 인식하여 사용자가 지정한 영역의 텍스트와 데이터를 정확하게 추출하는 서비스
가격은 아래와 같다.
OCR API 사용 방법
1. Domain 생성
Domain을 생성한 뒤옵션에 있는 API Gateway 연동을 선택한다.
1. API 호출
발급한 Secret Key와 Invoke URL을 저장해둔 뒤 이를 이용해 API 호출을 하면 된다.
[API 호출 방법]
POST
URL : Invoke URL
Header : X-OCR-SECRET, Content-Type
Body
{
"images": [
{
"format": "png",
"name": "medium",
"data": null,
"url":
"이미지 url"
}
],
"lang": "ko",
"requestId": "string",
"resultType": "string",
"timestamp": "{{$timestamp}}",
"version": "V1"
}3. Cloud Functions 흐름
1. S3 이벤트 트리거 설정
포트폴리오 파일에서 이미지 슬라이싱이 완료되면 해당 버킷에 completed.txt 파일을 업로드하여 업로드가 완료되었다는 트리거로 사용한다.
Cloud Functions 버킷 이벤트 생성을 누르고 정규표현식으로 필터를 걸어주면 된다.
userId/processed 위치에 업로드할 예정이기 때문에 '.*\/processed\/completed\.txt'로 넣어주었다.
2. Cloud Function 액션
빠른 개발을 위해 파이썬으로 작성하였고, NCP에는 액션을 테스트할 수는 없기 때문에 로컬에서 테스트한 뒤 올려주었다.
[S3 객체 목록 조회]
- boto3의 'list_objects_v2'를 이용해 해당 버킷의 객체 목록을 조회한다.
[각 이미지에 대해 Presigned GET URL 발급]
- 이미지 접근을 위해 버킷의 이미지들에 대해 PresignedUrl을 발급한다.
- 발급받은 PresignedUrl은OCR API을 호출할 때 사용한다.
[OCR 요청 병렬 처리]
- 이미지 수가 보통 50장 이상이기 때문에 병렬로 처리한다.
- ThreadPoolExecutor을 사용했다.
- 요청이 실패할 경우 최대 1회까지 재시도하는 로직을 추가했다.
[OCR 결과를 JSON으로 만들어 버킷에 업로드]
- OCR 결과를 합쳐 json 파일로 만든 뒤 버킷에 업로드한다.
3. Action 코드 구현
1. 환경 설정 및 클라이언트 초기화
환경변수를 불러오고 boto3를 이용해 S3 클라이언트를 생성해주었다.
NCP Object Storage는 S3 SDK와 호환되기 때문에 boto3를 사용하면 된다.
import os
import json
import time
import requests
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
import boto3
# S3 기본 설정
endpoint_url = "https://kr.object.ncloudstorage.com"
bucket_name = os.environ['bucket_name']
access_key = os.environ['access_key']
secret_key = os.environ['secret_key']
# OCR API 설정
ocr_api_url = os.environ['ocr_api_url']
ocr_secret = os.environ['ocr_secret']
headers = {
"Content-Type": "application/json",
"X-OCR-SECRET": ocr_secret
}
# S3 클라이언트 생성
s3 = boto3.client(
's3',
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
endpoint_url=endpoint_url
)
2. presigned URL 생성 함수
이미지 접근와 버킷에 json 파일을 업로드하기 위한 presignedUrl을 발급하는 함수다.
만료시간을 설정해 해당 시간 내에만 접근할 수 있어 보안에 이점이 있다.
def get_presigned_url(key):
return s3.generate_presigned_url(
ClientMethod='get_object',
Params={'Bucket': bucket_name, 'Key': key},
ExpiresIn=3600
)
def get_presigned_url_for_put(key):
return s3.generate_presigned_url(
ClientMethod='put_object',
Params={'Bucket': bucket_name, 'Key': key, 'ContentType': 'application/json'},
ExpiresIn=3600
)
3. OCR API 호출 함수 (단일 이미지 처리)
OCR Domain 생성 시 발급받은 URL와 Secret Key로 요청하면 된다.
요청 실패 시 최대 retry_count + 1번 (최대 2번까지) 재시도하게 하였고, 응답 중 inferText 값만 추출하여 텍스트 리스트로 반환하게 했다.
def process_image(idx, key, url, retry_count=1):
filename = os.path.basename(key)
payload = {
"images": [
{
"format": "png",
"name": f"image_{idx}",
"url": url
}
],
"lang": "ko",
"requestId": f"req_{idx}",
"resultType": "string",
"timestamp": int(time.time() * 1000),
"version": "V1"
}
for attempt in range(1, retry_count + 2):
try:
res = requests.post(ocr_api_url, headers=headers, json=payload)
if res.status_code == 200:
fields = res.json()['images'][0].get('fields', [])
texts = [f['inferText'] for f in fields]
return filename, texts
else:
print(f"⚠️ OCR 요청 실패 ({filename}) - 시도 {attempt}, 상태코드: {res.status_code}")
except Exception as e:
print(f"⚠️ OCR 예외 발생 ({filename}) - 시도 {attempt}, 오류: {str(e)}")
time.sleep(1)
return filename, [f"OCR failed after {retry_count + 1} attempts"]
4. S3 이벤트 처리 및 OCR 로직 실행
이미지 목록 조회 → 병렬로 OCR 실행 → 결과 저장 및 업로드
완료 시 "result.json" 파일을 생성하고 ocr 폴더에 업로드한다.
def process_s3_upload(event, context):
start_time = time.time()
print("🚀 이벤트 수신:", json.dumps(event, indent=2, ensure_ascii=False))
try:
key = event.get('object_name')
if not key:
return {"result": "error", "message": "object_name not provided in event"}
match = re.match(r"([^/]+)/processed/completed\.txt", key)
if not match:
print("❌ userId 경로 파싱 실패")
return {"result": "invalid path"}
user_id = match.group(1)
prefix = f"{user_id}/processed/"
print(f"📁 S3 목록 조회 중: {prefix}")
try:
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=prefix)
except Exception as e:
return {"result": "s3_list_error", "message": str(e)}
contents = response.get("Contents", [])
image_keys = [obj["Key"] for obj in contents if obj["Key"].endswith(".png")]
if not image_keys:
print("⚠️ 이미지 없음")
return {"result": "no images"}
print(f"✅ 이미지 {len(image_keys)}장 OCR 시작")
ocr_results = {}
with ThreadPoolExecutor(max_workers=4) as executor:
futures = [
executor.submit(process_image, idx, key, get_presigned_url(key))
for idx, key in enumerate(image_keys, start=1)
]
for future in as_completed(futures):
try:
filename, texts = future.result()
ocr_results[filename] = " ".join(texts)
print(f"✅ OCR 완료: {filename}")
except Exception as e:
print(f"❌ OCR 처리 실패 (Thread 내부): {str(e)}")
ocr_results[f"error_{time.time()}"] = f"Exception: {str(e)}"
result_key = f"{user_id}/ocr/result.json"
print("📝 OCR 결과:", result_key, ocr_results)
try:
upload_url = get_presigned_url_for_put(result_key)
except Exception as e:
return {"result": "presigned_url_error", "message": str(e)}
try:
res = requests.put(
upload_url,
data=json.dumps(ocr_results, ensure_ascii=False, indent=2).encode("utf-8"),
headers={'Content-Type': 'application/json'}
)
if res.status_code == 200:
print(f"✅ OCR 결과 presigned URL로 업로드 완료 → {result_key}")
else:
print(f"❌ 업로드 실패: {res.status_code}")
return {"result": "upload error", "status_code": res.status_code}
except Exception as e:
return {"result": "upload_exception", "message": str(e)}
elapsed = round(time.time() - start_time, 3)
print(f"✅ OCR 전체 완료, 처리 시간: {elapsed}s")
return {
"result": "success",
"image_count": len(image_keys),
"processing_time_sec": elapsed
}
except Exception as e:
print(f"❌ 최상위 오류 발생: {str(e)}")
return {"result": "error", "message": str(e)}
5. Cloud Function 진입점
Cloud Functions에서는 실행될 때 main() 함수가 호출되기 때문에 꼭 넣어주어야 한다.
입력 이벤트를 받아 process_s3_upload()가 실행되게 했다.
def main(args):
try:
result = process_s3_upload(args, None)
return result if isinstance(result, dict) else {"result": "invalid_return", "raw": str(result)}
except Exception as e:
print(f"❌ main() 예외 발생: {str(e)}")
return {"result": "error", "message": str(e)}
⬇️ 전체 코드 ⬇️
import os
import json
import time
import requests
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
import boto3
# S3 기본 설정
endpoint_url = "https://kr.object.ncloudstorage.com"
bucket_name = os.environ['bucket_name']
access_key = os.environ['access_key']
secret_key = os.environ['secret_key']
# OCR API 설정
ocr_api_url = os.environ['ocr_api_url']
ocr_secret = os.environ['ocr_secret']
headers = {
"Content-Type": "application/json",
"X-OCR-SECRET": ocr_secret
}
# S3 클라이언트 생성
s3 = boto3.client(
's3',
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
endpoint_url=endpoint_url
)
def get_presigned_url(key):
return s3.generate_presigned_url(
ClientMethod='get_object',
Params={'Bucket': bucket_name, 'Key': key },
ExpiresIn=3600
)
def get_presigned_url_for_put(key):
return s3.generate_presigned_url(
ClientMethod='put_object',
Params={'Bucket': bucket_name, 'Key': key, 'ContentType': 'application/json'},
ExpiresIn=3600
)
def process_image(idx, key, url, retry_count=1):
filename = os.path.basename(key)
payload = {
"images": [
{
"format": "png",
"name": f"image_{idx}",
"url": url
}
],
"lang": "ko",
"requestId": f"req_{idx}",
"resultType": "string",
"timestamp": int(time.time() * 1000),
"version": "V1"
}
for attempt in range(1, retry_count + 2):
try:
res = requests.post(ocr_api_url, headers=headers, json=payload)
if res.status_code == 200:
fields = res.json()['images'][0].get('fields', [])
texts = [f['inferText'] for f in fields]
return filename, texts
else:
print(f"⚠️ OCR 요청 실패 ({filename}) - 시도 {attempt}, 상태코드: {res.status_code}")
except Exception as e:
print(f"⚠️ OCR 예외 발생 ({filename}) - 시도 {attempt}, 오류: {str(e)}")
time.sleep(1)
# 모든 시도 실패 시
return filename, [f"OCR failed after {retry_count + 1} attempts"]
def process_s3_upload(event, context):
start_time = time.time()
print("🚀 이벤트 수신:", json.dumps(event, indent=2, ensure_ascii=False))
try:
key = event.get('object_name')
if not key:
return {"result": "error", "message": "object_name not provided in event"}
match = re.match(r"([^/]+)/processed/completed\.txt", key)
if not match:
print("❌ userId 경로 파싱 실패")
return {"result": "invalid path"}
user_id = match.group(1)
prefix = f"{user_id}/processed/"
print(f"📁 S3 목록 조회 중: {prefix}")
try:
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=prefix)
except Exception as e:
return {"result": "s3_list_error", "message": str(e)}
contents = response.get("Contents", [])
image_keys = [obj["Key"] for obj in contents if obj["Key"].endswith(".png")]
if not image_keys:
print("⚠️ 이미지 없음")
return {"result": "no images"}
print(f"✅ 이미지 {len(image_keys)}장 OCR 시작")
ocr_results = {}
with ThreadPoolExecutor(max_workers=4) as executor:
futures = [
executor.submit(process_image, idx, key, get_presigned_url(key))
for idx, key in enumerate(image_keys, start=1)
]
for future in as_completed(futures):
try:
filename, texts = future.result()
ocr_results[filename] = " ".join(texts)
print(f"✅ OCR 완료: {filename}")
except Exception as e:
print(f"❌ OCR 처리 실패 (Thread 내부): {str(e)}")
ocr_results[f"error_{time.time()}"] = f"Exception: {str(e)}"
result_key = f"{user_id}/ocr/result.json"
print("📝 OCR 결과:", result_key, ocr_results)
# presigned URL로 결과 업로드
try:
upload_url = get_presigned_url_for_put(result_key)
except Exception as e:
return {"result": "presigned_url_error", "message": str(e)}
try:
res = requests.put(
upload_url,
data=json.dumps(ocr_results, ensure_ascii=False, indent=2).encode("utf-8"),
headers={'Content-Type': 'application/json'}
)
if res.status_code == 200:
print(f"✅ OCR 결과 presigned URL로 업로드 완료 → {result_key}")
else:
print(f"❌ 업로드 실패: {res.status_code}")
return {"result": "upload error", "status_code": res.status_code}
except Exception as e:
return {"result": "upload_exception", "message": str(e)}
elapsed = round(time.time() - start_time, 3)
print(f"✅ OCR 전체 완료, 처리 시간: {elapsed}s")
return {
"result": "success",
"image_count": len(image_keys),
"processing_time_sec": elapsed
}
except Exception as e:
print(f"❌ 최상위 오류 발생: {str(e)}")
return {"result": "error", "message": str(e)}
def main(args):
try:
result = process_s3_upload(args, None)
return result if isinstance(result, dict) else {"result": "invalid_return", "raw": str(result)}
except Exception as e:
print(f"❌ main() 예외 발생: {str(e)}")
return {"result": "error", "message": str(e)}
4. 트러블 슈팅
네트워크 구성
Cloud Functions VPC 연결에 들어가면 아래 글이 적혀있다.
VPC를 선택하면 하위의 Subnet 목록을 확인할 수 있습니다. 액션 당 하나의 VPC만 선택할 수 있으며, VPC에 속한 Subnet 중 Private Subnet만 선택 가능합니다. 단, 하나의 Subnet만 추가할 수 있습니다.
VPC 액션에서 인터넷 연결을 위해 Subnet의 NAT Gateway를 설정해야 합니다. VPC/Subnet 생성, 설정 등 자세한 사항은 VPC 상품 설명서에서 확인할 수 있습니다.( 필수 입력 사항입니다.)
- 1개의 Action은 1개의 VPC를 선택할 수 있고, 해당 서브넷 중 Private 서브넷에만 연결할 수 있다.
- 또한 현재는 VPC 내 KR-2 존에 생성한 Subnet에만 접근할 수 있다.
처음에는 이렇게만 구성을 했었는데 계속 아래와 같이 객체를 가져올 수 없다는 에러가 났다.
{ "message": "Connect timeout on endpoint URL: \"https://kr.object.ncloudstorage.com/onepiece?list~", "result": "error", "stage": "s3_list" }
Cloud Function에서 NCP Object Storage Endpoint로 연결이 안 되고 있어 다시 확인해보니 Cloud Function 실행 환경이 Private VPC에 속해 있기 때문에 외부 인터넷에 접근할 수 없는 것이 원인이었다. (외부와 통신하는 코드가 포함되어 있다.)
따라서, 아래 사진과 같이 NAT Gateway를 만들어 이를 통해 외부로 나갈 수 있게 해주었다.
[NAT Gateway 생성]
[Route Table에 NAT Gateway 연결]
자동으로 만들어져있는 private-table 라우팅 테이블에 0.0.0.0/0으로 생성한 NAT Gateway를 연결해준다.
이렇게 구성해주니 외부와 잘 통신이 되었다.
'Experience > 디프만' 카테고리의 다른 글
| [NCP] NCP 사용 후기 (디프만 x Green Developers) (0) | 2025.04.10 |
|---|---|
| [코드 포맷팅] spotless로 코드 포맷팅하고 Git Pre-commit으로 자동화하기 (1) | 2025.01.31 |